S3サーバーアクセスログを分析する
S3アクセスログをAthenaで分析する際に必要な設定メモ
パーティションやらなんやらはまだ理解していない&S3アクセスログ以外も今後追加していこう。
図にするとこんな感じ、3つの領域に分けて記載します。赤点線、青点線、緑点線
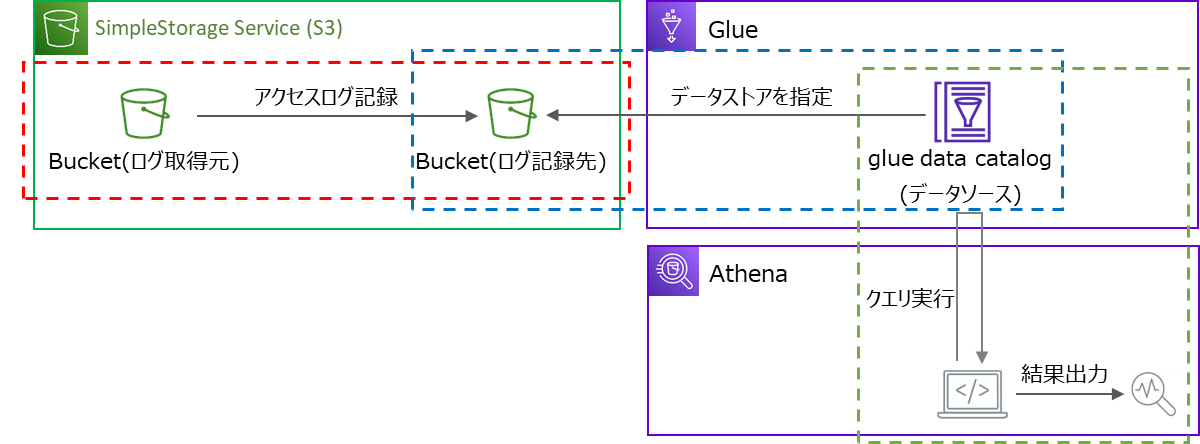
S3サーバーアクセスログの記録(赤点線)
下記リンクの通りです。
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/userguide/ServerLogs.html
- S3バケットの作成
-
手順は割愛します。
①ログ取得元S3バケットの作成
②ログ記録先S3バケットの作成
- ログ取得元S3バケットのサーバーアクセスのログ記録を有効化
-
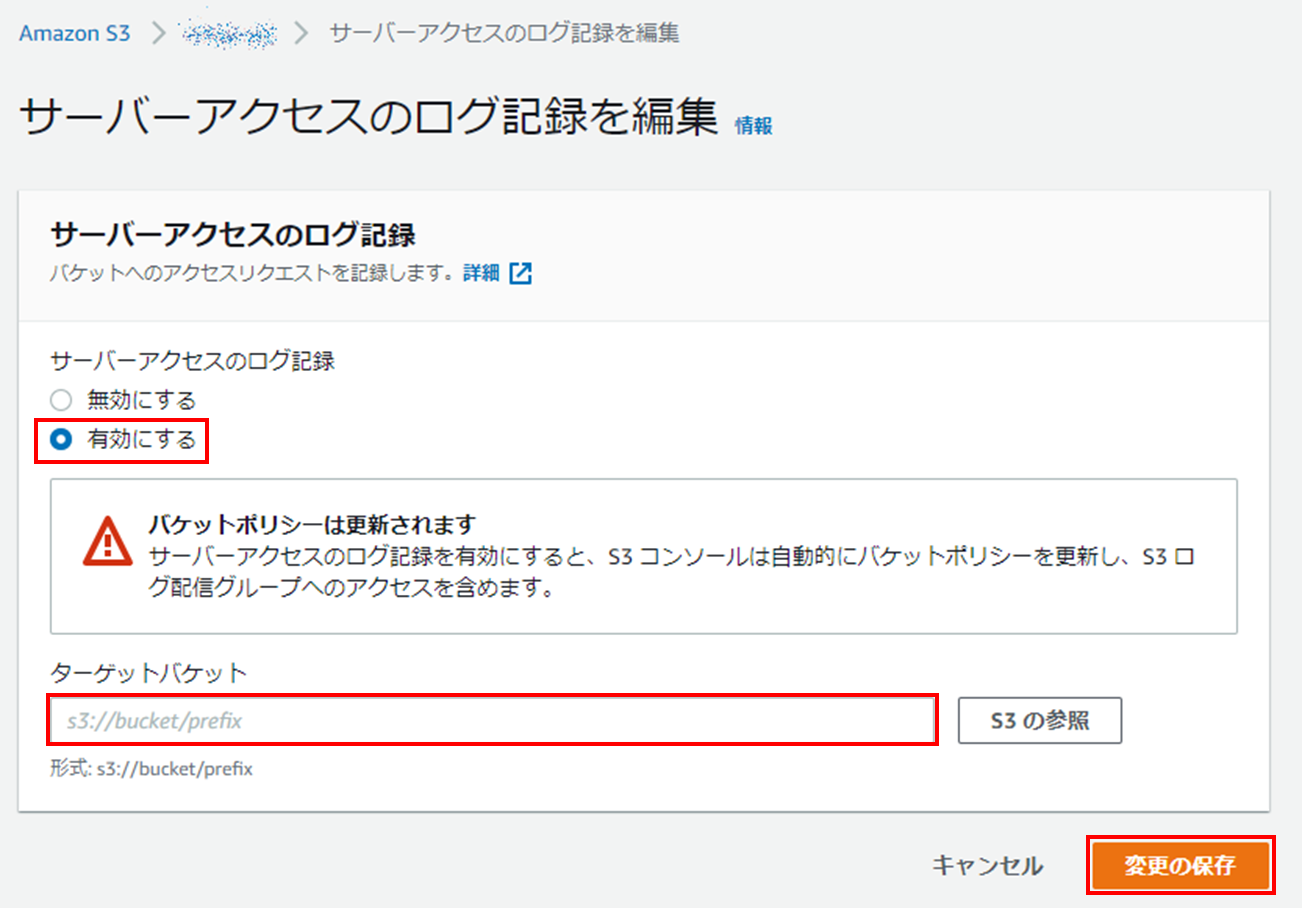
①ログ取得元S3バケットの[プロパティ]-[サーバーアクセスのログ記録]の[編集]をクリックします。

②以下を設定し[変更の保存]をクリックします。
・サーバーアクセスのログ記録:有効
・ターゲットバケット:ターゲットバケットのS3 URIを指定(キープレフィックスの付与を推奨)
※複数のバケットが同じターゲットバケットにログを記録する場合に、ソースバケットを区別するためにも役立ちます。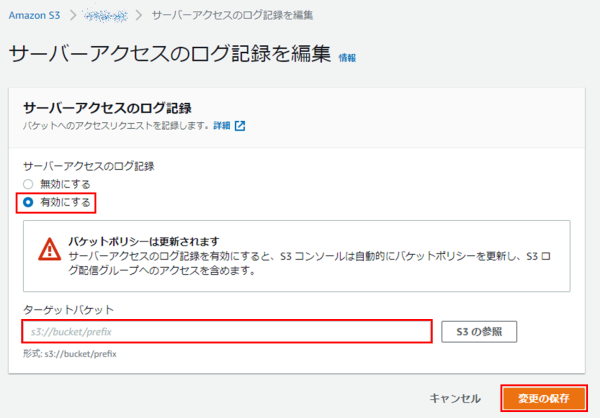

S3サーバーアクセスログのデーターベース、テーブル作成(青点線)
下記リンクの通りです。
https://aws.amazon.com/jp/premiumsupport/knowledge-center/analyze-logs-athena/
- Athenaからデーターベース、テーブルの作成
-
①Athenaコンソールからクエリエディタを開きます
②データベースを作成します(データベース名は変更可能です)
create database s3_access_logs_db
③テーブルを作成します(1行目のテーブル名は変更可能です、35行目のバケットは自身の環境に合わせます)
CREATE EXTERNAL TABLE `s3_access_logs_db.mybucket_logs`( `bucketowner` STRING, `bucket_name` STRING, `requestdatetime` STRING, `remoteip` STRING, `requester` STRING, `requestid` STRING, `operation` STRING, `key` STRING, `request_uri` STRING, `httpstatus` STRING, `errorcode` STRING, `bytessent` BIGINT, `objectsize` BIGINT, `totaltime` STRING, `turnaroundtime` STRING, `referrer` STRING, `useragent` STRING, `versionid` STRING, `hostid` STRING, `sigv` STRING, `ciphersuite` STRING, `authtype` STRING, `endpoint` STRING, `tlsversion` STRING) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe' WITH SERDEPROPERTIES ( 'input.regex'='([^ ]*) ([^ ]*) \\[(.*?)\\] ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) (\"[^\"]*\"|-) (-|[0-9]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) (\"[^\"]*\"|-) ([^ ]*)(?: ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*))?.*$') STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 's3://awsexamplebucket1-logs/prefix/'
S3サーバーアクセスログの分析(緑点線)
クエリの例に習って、クエリを実行します。
- クエリの例
-
そのうち追加します、公式ページのもご参考に!
https://aws.amazon.com/jp/premiumsupport/knowledge-center/analyze-logs-athena/
・ライフサイクルルールによって実行されたログを抽出して、requestdatetimeで並び替え
SELECT * FROM s3_access_logs_db.mybucket_logs WHERE operation LIKE 'S3%' ORDER BY requestdatetime ASC