Script:Python:StockPriceForecast
⚠️ この記事は最終更新から1年以上が経過しています。情報が古い可能性があるためご注意ください。
目次
Python/株価予測
はじめに
機械学習用の株価予測で使用したスクリプトです。
以下の情報から、予測したい銘柄の明日の株価予測をしています。
・ダウ平均株価
・日経先物株価
・予測したい銘柄の株価
スクリプト
#モジュールの読み込み
import pandas as pd
from sklearn.model_selection import train_test_split
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Activation
from keras import optimizers
from keras.layers.core import Dropout
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error
from keras.callbacks import EarlyStopping, LearningRateScheduler
from sklearn.metrics import r2_score
from sklearn.preprocessing import StandardScaler
import matplotlib.dates as dates
# CSVファイルの読み込み
DJI = pd.read_csv("^DJI.csv", parse_dates=['Date'], index_col=0, encoding='cp932', engine='python') #csvデータを読み込む
CME = pd.read_csv("NIY=F.csv", parse_dates=['Date'], index_col=0, encoding='cp932', engine='python') #csvデータを読み込む
Target = pd.read_csv("8267.T.csv", parse_dates=['Date'], index_col=0, encoding='cp932', engine='python') #csvデータを読み込む
# 株価の日付調整(時差を考慮)
Target = Target.shift(-1)
# CME = CME.shift(-1)
# データの結合をする
join_data1 = pd.merge(CME[["Adj Close"]], DJI[["Adj Close"]], on="Date", how = "left")
join_data1 = pd.merge(join_data1, Target [["Adj Close"]], on="Date", how = "left")
# 欠損データを直前の値(行)で補完
join_data1 = join_data1.fillna(method='ffill')
# 値動きの差分を取得
join_data2 = join_data1.diff()
# 欠損データ(行)を削除する
join_data3 = join_data2.dropna(how='any', axis=0)
# 株価の日付調整(時差を考慮)
join_data3 = join_data3[:-1]
# データセットの標準化(ただのメモ)
"""
scaler = StandardScaler()
scaler.fit(join_data3)
join_data3 = scaler.transform(join_data3)
"""
# データの分割
(train, test) = train_test_split(join_data3, test_size=0.4, shuffle=True)
# 訓練用データ、評価データ
x_train = train.iloc[:, [0, 1]]
y_train = train.iloc[:, [2]]
# テストデータ
x_test = test.iloc[:, [0, 1]]
y_test = test.iloc[:, [2]]
# 入力層のunit数
input_units = 2
# 出力層のunit数
output_units = 1
# 学習回数、バッチサイズ
epochs = 100
batch = 16
# モデルの構築
model = Sequential()
model.add(Dense(input_units, input_dim=len(x_train.columns)))
model.add(Activation("linear"))
model.add(Dense(output_units))
model.summary()
optimizer = optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=0, decay=0.0, amsgrad=False)
#optimizer = optimizers.Adagrad(lr=0.01, decay=0.0)
model.compile(loss='mean_squared_error', optimizer=optimizer)
# 学習オプション
history = model.fit(x_train, y_train, verbose=2, epochs=epochs, batch_size=batch, validation_data=(x_test, y_test))
# 株価の日付調整
join_data3 = join_data3.shift(freq='D')
# 実データ
infact_data = join_data3.iloc[:, [2]]
infact_data = infact_data.tail(30)
# 予測データ
join_data3 = join_data3.tail(30)
predict_data1 = pd.DataFrame(model.predict(join_data3.iloc[:, [0, 1]]))
predict_data2 = pd.DataFrame(model.predict(join_data2.iloc[[-1], [0, 1]]))
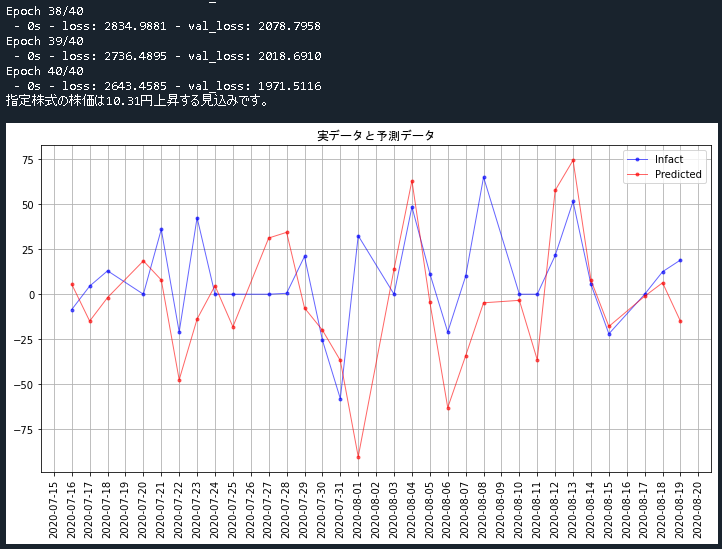
print("指定株式の株価は" + str('{:.2f}'.format(predict_data2.iloc[0,0])) + "円上昇する見込みです。")
# Infact(実データ)とPredicted(予測データ)をグラフに表示
fig, ax = plt.subplots(figsize=(12,6))
ax.set_title('実データと予測データ', fontname="MS Gothic")
# 実データ
ax.plot(join_data3.index, infact_data, 'b', alpha=0.6, marker='.', label='Infact', linewidth=1)
# 予測データ
ax.plot(join_data3.index, predict_data1, 'r', alpha=0.6, marker='.', label='Predicted', linewidth=1)
ax.tick_params(axis='x', labelrotation= 90)
ax.xaxis.set_major_locator(dates.DayLocator(bymonthday=None, interval=1, tz=None))
ax.legend()
ax.grid(True)
plt.show()
# model.reset_states()
実行結果
実行結果は以下のようになります。
Script/Python/StockPriceForecast.txt · 最終更新: by 127.0.0.1